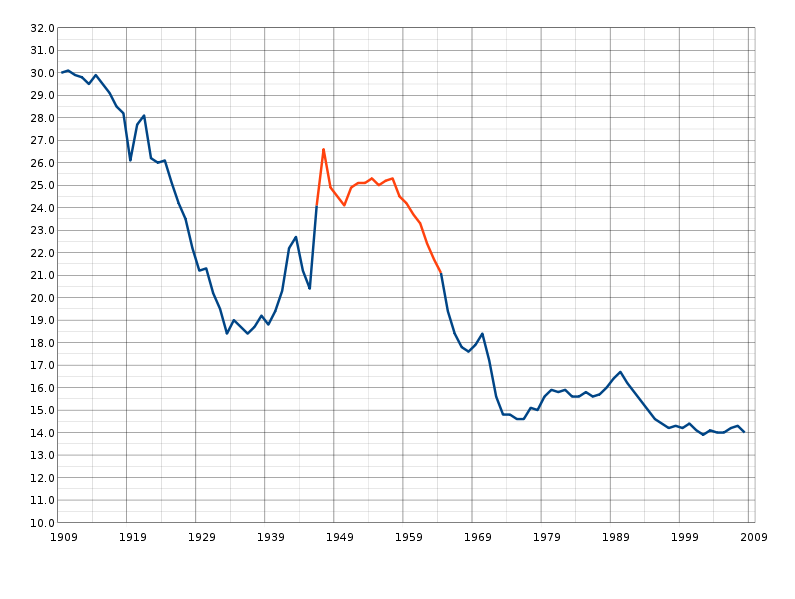
The goal of measures of central tendency is to come up with the one single number that best describes a distribution of scores. They let us know if the distribution of scores tends to be composed of high scores or low scores.
Three measures of central tendency are commonly used in statistical analysis – the mode, the median, and the mean. Each measure is designed to represent a typical score. The choice of which measure to use depends on:
- the shape of the distribution (whether normal or skewed), and
- the variable’s “level of measurement” (data are nominal, ordinal or interval).
Remember, measures of central tendency look for the one number which best describe all of the numbers.
Appropriate Measures of Central Tendency
- Nominal variables -Mode
- Ordinal variables -Median
- Interval level variables –Mean, if the distribution is normal (median is better with skewed distribution)
Mode
Mode is the most common outcome. It is the most common observation in a group of scores. Distributions can be unimodal, bimodal, or multimodal.
If the data is categorical (measured on the nominal scale) then only the mode can be calculated.
The mode can also be calculated with ordinal and higher data, but it often is not appropriate. If other measures can be calculated, the mode would never be the first choice!
7, 7, 7, 20, 23, 23, 24, 25, 26 has a mode of 7, but obviously it doesn’t make much sense.
Median
Median is the middle-most value. 50% of observations are above the median, 50% are below it. The difference in magnitude between the observations does not matter. Therefore, it is not sensitive to outliers.
Formula Median = n + 1 / 2
To compute the median
- First you rank order the values of X from low to high: è 85, 94, 94, 96, 96, 96, 96, 97, 97, 98
- then count number of observations = 10.
- add 1 = 11.
- divide by 2 to get the middle score è the 5½ score
- here 96 is the middle score score
Thus median is the number that divides a distribution of scores exactly in half. The median is the same as the 50th percentile. It is better than mode because only one score can be median and the median will usually be around where most scores fall. If data are perfectly normal, the mode is the median. The median is computed when data are ordinal scale or when they are highly skewed.
Mean – Average
Mean is the most common measure of central tendency. It is the best for making predictions and is applicable under two conditions:
- scores are measured at the interval level, and
- distribution is more or less normal [symmetrical].
Mean is the arithmetic average, computed simply by adding together all scores and dividing by the number of scores. It uses information from every single score.
If the distribution is normal, mean is the best measure of central tendency as most scores “bunched up” in middle. Extreme scores occur less frequent thus they don’t move mean around.
If data are perfectly normal, then the mean, median and mode are exactly the same. I would prefer to use the mean whenever possible since it uses information from EVERY score.
Measures of Central Tendency -The Shape of Distributions
- With perfectly bell shaped distributions, the mean, median, and mode are identical.
- With positively skewed data, the mode is lowest, followed by the median and mean.
- With negatively skewed data, the mean is lowest, followed by the median and mode.
Using the Mean to Interpret Data Describing the Population Mean
Remember, we usually want to know population parameters, but populations are too large. So, we use the sample mean to estimate the population mean.
How well does the mean represent the scores in a distribution? The logic here is to determine how much spread is in the scores. How much do the scores “deviate” from the mean? Think of the mean as the true score or as your best guess. If every X were very close to the Mean, the mean would be a very good predictor.
If the distribution is very sharply peaked then the mean is a good measure of central tendency and if you were to use the mean to make predictions you would be right or close much of the time
Why can’t the mean tell us everything?
Mean describes central tendency, what the average outcome is. We also want to know something about how accurate the mean is when making predictions. The question becomes how good a representation of the distribution is the mean? How good is the mean as a description of central tendency — or how good is the mean as a predictor?
Answer — it depends on the shape of the distribution. Is the distribution normal or skewed?
What if scores are widely distributed?
The mean is still your best measure and your best predictor, but your predictive power would be less.
How do we describe this?